Neural Pocket: Eine Fallstudie zu Unity Computer Vision
Das Trainieren von Computer Vision-Modellen auf Produktionsniveau ist keine leichte Aufgabe und erforderte in der Vergangenheit, dass Teams reale Daten sammelten und mühsam kommentierten - ein zeit- und ressourcenaufwändiger Prozess. Neural Pocket nutzt synthetische Datensätze, die mit Unity Computer Vision generiert wurden, um diese Herausforderungen bei Computer-Vision-Aufgaben zu meistern.
-
Die Herausforderung
Schnelle Generierung großer Datenmengen mit perfekten Annotationen für das Modelltraining für Computer Vision.
-
Produkte
Unity Pro, Unity Computer Vision Perception-Paket
-
Teammitglieder
11 (1 Simulationsingenieur, 10 KI-Ingenieure)
-
Standort
Tokio, Japan

Schnelleres, besseres und kostengünstigeres Computer Vision-Training
Neural Pocket hat seinen Hauptsitz in Tokio und bietet End-to-End-Smart-City-KI-Lösungen für große Unternehmen und Regierungsstellen in Japan und darüber hinaus. Durch die Nutzung der Echtzeit-3D-Entwicklungsplattform von Unity und des Unity Computer Vision Perception-Pakets trainiert das Team Computer Vision-Modelle schneller, kostengünstiger und effektiver.

Die Ergebnisse
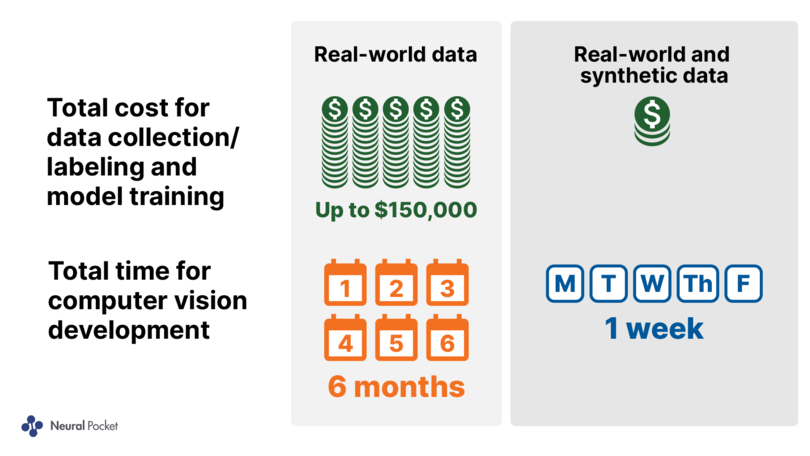
- 95 % Zeitersparnis bei den Computer Vision Modelltrainingszyklen (1 Woche gegenüber durchschnittlich bis zu 6 Monaten)
- 95 % weniger Kosten für Datenerfassung, Annotation und Training
- Verbesserte Leistung von Computer Vision-Modellen
- Verbesserte Fähigkeiten, um mehrere Projekte zu übernehmen und das Umsatzwachstum zu steigern
Ergebnisse zu einem Bruchteil der Zeit und der Kosten
Die Herausforderungen der realen Datenerfassung und Annotation in Kombination mit der iterativen Natur des Modelltrainings für Computer Vision können teuer und zeitaufwändig sein. Bei Neural Pocket erfordert das Trainieren eines Modells mit realen Daten in der Regel zahlreiche Iterationen, oft bis zu 30 Trainingszyklen.
Jeder dieser Zyklen erfordert die Erfassung von Daten aus der realen Welt (z. B. Video-, Foto- und/oder Drohnenaufnahmen), die Annotation (d. h. die manuelle Kennzeichnung durch ein Team von Annotatoren), das Training und die anschließende Bewertung, was im Durchschnitt etwa eine Woche pro Zyklus dauert. Bei Projekten mit bis zu 30 Zyklen können sich die Kosten auf bis zu 150.000 US-Dollar belaufen, und die Zeitspanne bis zur Bereitstellung eines produktionsreifen Modells kann sechs Monate betragen.
Durch den Einsatz von Unity und dem Unity Computer Vision Perception Paket konnte das Neural Pocket Team die Anzahl der Iterationen und die damit verbundenen Kosten für das Trainieren von Computer-Vision-Modellen erheblich reduzieren und gleichzeitig die Gesamtleistung des Modells steigern. Das Team verwendet die Tools von Unity, um synthetische Bilder zu generieren, die automatisch beschriftet und mit Anmerkungen versehen werden, um ein iteratives Modelltraining für Computer Vision mit einer Kombination aus realen und simulierten Daten zu ermöglichen.
Bei Verwendung synthetischer Daten, die mit dem Unity Computer Vision Perception Paket erstellt wurden, und nur einem Trainingszyklus mit realen Daten, kann ein leistungsfähigeres Modell in etwas mehr als einer Woche erstellt werden, was im Durchschnitt eine Zeit- und Kostenersparnis von etwa 95 % bedeutet.
Sehen wir uns an, wie das Team das Unity Computer Vision Perception Paket auf unterschiedliche Weise für zwei sicherheitsbezogene Projekte eingesetzt hat.

Projekt 1: Objekterkennung für Waffen
Bei diesem Projekt wollte einer der Partner von Neural Pocket eine sicherere Umgebung in einem seiner Büros schaffen. Neural Pocket wurde mit der Entwicklung eines Computer Vision-Modells für sein intelligentes Sicherheitskamerasystem beauftragt, um gefährliche Objekte richtig zu erkennen.
Um Daten aus der realen Welt für das Computer Vision-Training zu sammeln, inszenierte Neural Pocket einen Videodreh und filmte Teilnehmer, die Waffen wie Messer, Schläger und Pistolen in einer Reihe von leicht bis schwer zu erkennenden Ausrichtungen trugen. Neural Pocket erstellte dann ungefähr 1.000 Standbilder aus den Videos und identifizierte die Waffen, indem es sein internes Annotatorenteam beauftragt hat, jedes Bild manuell zu beschriften.
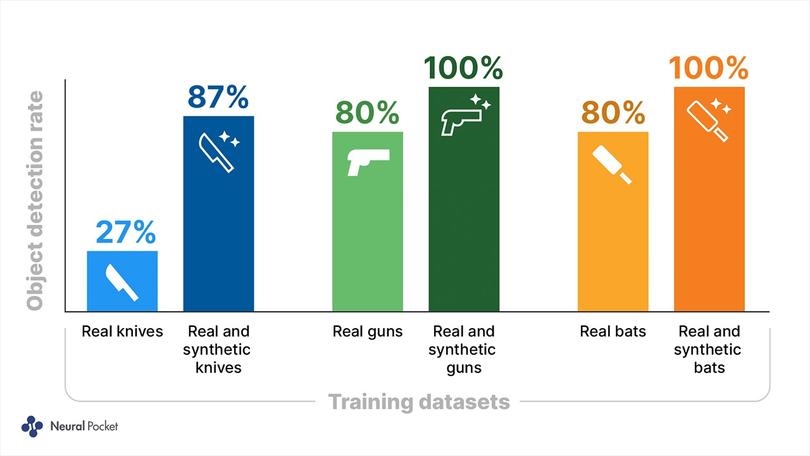
Nach der Verwendung dieser Daten für den ersten Trainingszyklus betrug die Erkennungsrate 27 % für Messer und 80 % für Schläger und Schusswaffen.
Erfolgreiche Kombination: Echte und synthetische Daten
Um die Leistung zu steigern, wandte sich Neural Pocket an das Unity Computer Vision Perception Paket, um umfangreiche Datensätze für das Training und die Validierung von Computer Vision zu generieren.
„Das Unity Computer Vision Perception Paket ermöglicht einen organisierten Ablauf und eine klare Struktur und ist in jedem Erkennungsprojekt in hohem Maße wiederverwendbar”, sagte Romain Angénieux, Leiter der Simulation bei Neural Pocket. „Mit einer Reihe anpassbarer Komponenten wie Szenarien, Randomizer, Tags, Labels und Smart Cameras konnten wir Randomisierungen auf sehr einfache und flexible Weise über die Benutzeroberfläche einrichten.“
Neural Pocket hat 3D-Waffenmodelle aus dem Unity Asset Store und anderen Marktplätzen bezogen und sie problemlos in die Computer Vision-Tools von Unity für die benutzerdefinierte Objekterkennung integriert. Das Team hat verschiedene Aspekte der Simulation zwischen den aufgenommenen Frames randomisiert wie z. B. das Rendern von Bildern mit Händen, die Waffen halten und von Bildern, in denen nur die Waffen zu sehen sind.
Unity Computer Vision bietet eine skalierbare Lösung zur Erstellung von Tausenden und sogar Millionen von synthetischen Bildern. Neural Pocket generierte 5.100 simulierte Frames – fünfmal mehr als die Anzahl der realen Frames. Nachdem das Modell mit einer Kombination aus realen und synthetischen Daten trainiert wurde, erreichten die Ergebnisse Produktionsqualität: Die Erkennungsrate von Messern stieg von 27 % auf 87 %, die von Schlägern und Schusswaffen von 80 % auf perfekte 100 %.
„Wir waren angenehm überrascht, dass wir auf Anhieb großartige Ergebnisse erzielen konnten”, so Alex Daniels, Senior Expert und Leiter des Technology Incubation Teams. „Mit der Möglichkeit, Parameter einfach und schnell zu ändern, um neue, verbesserte Datensätze zu generieren, und ohne die Abhängigkeit von der realen Datenerfassung, wurde unser Prozess der Datensatzerstellung deutlich rationalisiert.”

Projekt 2: Objekterkennung für Smartphones
In einem anderen Projekt versuchte ein Partner von Neural Pocket, eine KI zu trainieren, die Personen erkennt, die mit ihrem Smartphone Bilder aufnehmen, um vertrauliche Informationen wie Kreditkartennummern besser zu schützen.
Während das Team für das Projekt zur Erkennung gefährlicher Objekte bereits das sofort einsatzbereite Unity Computer Vision Perception Paket verwendete, nutzte es für dieses komplexere Projekt die Vorteile der Erweiterbarkeit und der Open-Source-Codebasis des Pakets.
„Die Verwendung der Standardkonfiguration des Perception-Pakets reicht aus, um die Computer-Vision-Leistung konsequent zu steigern, aber es kann noch viel mehr auf die bestehenden Tools aufgebaut werden, um einen möglichst großen Bereich abzudecken“, sagte Angénieux.
Das Team erstellte eine Reihe von benutzerdefinierten Randomisierungen, um die folgenden technischen Herausforderungen im Zusammenhang mit der Erkennung von Smartphones zu bewältigen:
- Eine breite Palette von Modellen – Entwicklung einer logischen Methode zur Kombination verschiedener Basiskomponenten (z. B. Logos, Kameras), um realistische 3D-Modelle von marktüblichen Handys zu erstellen.
- Eine unendliche Anzahl möglicher Handyhüllen-Designs – Durchführung von Texture Mapping, damit jedes Google Images API-Bild den Handyhüllen zugeordnet werden kann.
- Auf unterschiedliche Weise gehalten und teilweise von Fingern bedeckt – Erstellte modulare Hände in verschiedenen Posen und Hautvariationen.
- Viele Objekte könnten fälschlicherweise für ein Smartphone gehalten werden – Es wurden nicht-annotierte Fallenobjekte erstellt: Objekte, die eine ähnliche Form und einen ähnlichen Stil wie Smartphones haben, aber nicht erkannt werden sollten, wodurch der Gedanke eingeführt wird, dass „nicht jedes rechteckige, in der Hand gehaltene, Objekt unbedingt ein Handy sein muss”, und es werden Falsch-Positive reduziert.

Simulation steigert erneut die Leistung
Neural Pocket hat 20.540 reale Bilder erfasst und 27.478 synthetische Bilder erzeugt. Mit Daten aus der realen Welt allein lag die Erkennungsrate bei 89,8 %; mit realen und simulierten Datensätzen verbesserte sie sich auf 92,9 %.
„Dies mag wie eine kleine Verbesserung erscheinen, aber da die Erkennung von Handys über eine Reihe von Videobildern erfolgt, kann ein Zuwachs von 3 % bei statischen Bildern zu einer signifikanten Verbesserung der Erkennungsraten für Handys insgesamt führen”, so Daniels.

Was kommt als Nächstes
Da Unity Neural Pocket geholfen hat, seinen Durchsatz drastisch zu erhöhen, kann das Team nun mehr Aufgaben übernehmen und sein Umsatzpotenzial erweitern. Neural Pocket wendet die Computer Vision-Tools von Unity weiterhin in verschiedenen Projekten an; weitere Beispiele finden Sie in diesem Blogpost.
Für die Zukunft plant Neural Pocket, seine Abhängigkeit von realen Daten zu verringern und synthetische Daten für bis zu 90 % der Trainingsdaten zu verwenden. Das Vertrauen des Teams in die Computer-Vision-Fähigkeiten von Unity ist ein Schlüsselfaktor für diesen Wandel.
„Wir erwarten, dass sich das Unity Computer Vision Perception-Paket mit seiner aktiven Entwicklung, die sich an den Bedürfnissen der Benutzer orientiert, im Laufe der Zeit weiter verbessert und zu einer Referenz für Wahrnehmungsaufgaben und einem Ausgangspunkt für unsere Wahrnehmungsprojekte wird“, sagte Angénieux.

„Mit den Computer Vision-Tools von Unity können wir schneller und kostengünstiger arbeiten. Dadurch können wir unsere Computer Vision-Modelle mit einem Bruchteil des üblichen Zeit- und Kostenaufwands trainieren und bereitstellen.“

„Mit der zunehmenden Vielfalt an Daten, die Unity Computer Vision liefert, verringert sich die Notwendigkeit, Daten in der realen Welt zu sammeln. Auch die Leistung der Computer Vision-Modelle wird verbessert, was zu qualitativ hochwertigeren Produkten führt.”