Neural Pocket: A Unity Computer Vision case study
Training computer vision models to production-level quality is no small feat and has historically required teams to collect and painstakingly annotate real-world data, a time- and resource-intensive process. Neural Pocket is leveraging synthetic datasets generated using Unity Computer Vision to overcome these challenges for computer vision tasks.
-
The challenge
Generate large amounts of data quickly with perfect annotations for computer vision model training
-
Products
Unity Pro, Unity Computer Vision Perception Package
-
Team members
11 (1 simulation engineer, 10 AI engineers)
-
Location
Tokyo, Japan

Faster, better and more affordable computer vision training
Headquartered in Tokyo, Neural Pocket provides end-to-end smart city AI solutions for large companies and government entities in Japan and beyond. By leveraging Unity’s real-time 3D development platform and Unity Computer Vision Perception Package, its team is training computer vision models faster, cheaper and more effectively.

The results
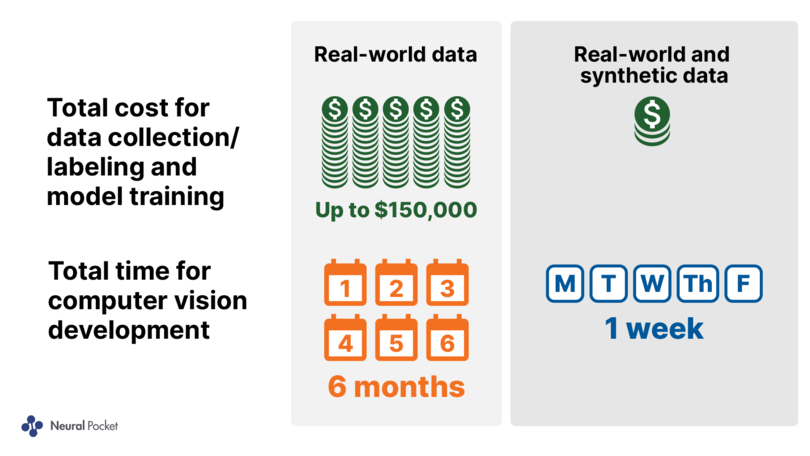
- 95% reduction in time for computer vision model training cycles (1 week vs up to 6 months, on average)
- 95% reduction in costs for data collection, annotation and training
- Improved computer vision model performance
- Improved capabilities to take on multiple projects and drive revenue growth
Results at a fraction of the time and cost
The challenges of real-world data collection and annotation combined with the iterative nature of computer vision model training can be expensive and time consuming. For Neural Pocket, training a model on real-world data typically requires numerous iterations, often as many as 30 training cycles.
Each of these cycles requires capturing real-world data (e.g., video, photo and/or drone capture), annotation (i.e., manual labeling by a team of annotators), training and then evaluation, which on average takes about one week per cycle. For projects that reach 30 cycles, costs can run as high as $150,000 and timelines can stretch to six months to deploy a production-ready model.
Leveraging Unity and the Unity Computer Vision Perception Package, the Neural Pocket team has significantly reduced the number of iterations and associated costs needed to train computer vision models, while boosting the overall model performance. The team uses Unity’s tools to generate synthetic images that are automatically labeled and annotated for iterative computer vision model training on a combination of real and simulated data.
When using synthetic data created with Unity Computer Vision Perception Package and only one cycle of training on real-world data, a more performant model can be created in just over one week, essentially saving approximately 95% in both time and money, on average.
Let’s explore how the team leveraged the Unity Computer Vision Perception Package in different ways for two security-related projects.

Project 1: Object detection for weapons
For this project, one of Neural Pocket’s partners wanted to provide a safer environment at one of its offices. It engaged Neural Pocket to develop a computer vision model for its smart security camera system to properly detect dangerous objects.
To collect real-world data for computer vision training, Neural Pocket staged a video shoot and filmed participants carrying weapons, such as knives, bats and guns, in a range of easy- to difficult-to-detect orientations. Neural Pocket then created approximately 1,000 still images from the videos and identified the weapons by engaging its internal team of annotators to manually label each image.
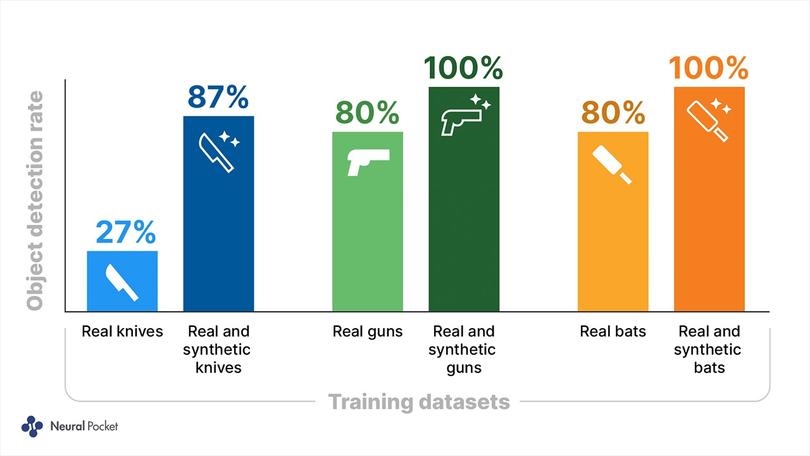
After using these data for its initial training cycle, the detection rate was 27% for knives and 80% for bats and guns.
Winning combination: Real and synthetic data
To boost performance, Neural Pocket turned to the Unity Computer Vision Perception Package for generating large-scale datasets for computer vision training and validation.
“Unity Computer Vision Perception Package allows for an organized flow and structure, and is highly reusable across any detection project,” said Romain Angénieux, Head of Simulation at Neural Pocket. “With a set of customizable components such as scenarios, randomizers, tags, labels and smart cameras, it allowed us to set up randomizations in a very straightforward and flexible way through its UI.”
Neural Pocket sourced 3D models of weapons from the Unity Asset Store and other marketplaces, and easily integrated them into Unity’s computer vision tools for custom object detection. The team randomized various aspects of its simulation between captured frames, such as rendering images with hands holding weapons and just the weapons in isolation.
Unity Computer Vision offers a scalable solution to create thousands and even millions of synthetic images. Neural Pocket generated 5,100 simulated frames – five times more than the number of real frames. After training the model on a combination of real and synthetic data, the results reached production quality levels: Knives jumped from a 27% to 87% detection rate, while bats and guns jumped from 80% to a perfect 100%.
“We were pleasantly surprised to get great results right out the box,” said Alex Daniels, Senior Expert and Head of the Technology Incubation Team. “With the ability to easily and quickly change parameters to generate new improved datasets, and no dependency on real-world data collection, our dataset creation process was significantly more streamlined.”

Project 2: Object detection for smartphones
On another project, a partner of Neural Pocket sought to train an AI to detect people taking pictures with their smartphone, to better protect confidential information such as credit card numbers.
While the team used the Unity Computer Vision Perception Package out of the box for the dangerous object detection project, it took advantage of the package’s extensibility and open source codebase for this more complex project.
“Using the default configuration of the Perception Package is enough to get a consequent boost in terms of computer vision performance, but much more can be built on top of the existing tools to cover as large a domain as possible,” said Angénieux.
The team created a series of custom randomizations to overcome the following technical challenges related to recognizing smartphones:
- A wide range of models – Designed a logical method of combining various base components (e.g., logos, cameras) to generate realistic 3D models of phones representative of the market.
- An infinite number of possible phone case designs – Performed texture mappings so that any Google Images API image could be mapped to the phone cases.
- Held and partially covered by fingers in different ways – Created modular hands in different poses and skin variations.
- Many objects could be mistaken for a smartphone – Created non-annotated trap objects: objects that have a similar shape and style to smartphones, but should not be detected, thus introducing the notion that “not every held rectangular object is necessarily a phone” and reducing false positives.

Simulation boosts performance again
Neural Pocket captured 20,540 real images and generated 27,478 synthetic images. On real-world data alone, the detection rate was 89.8%; using real and simulation datasets, this improved to 92.9%.
“While this may seem like a small improvement, because the phone detection is run over a series of video frames, a gain in 3% on static images can lead to a significant gain in detection rates for phones as a whole,” said Daniels.

What’s next
Because Unity has helped Neural Pocket dramatically increase its throughput, the team is now free to take on more work and expand its revenue potential. Neural Pocket continues to apply Unity’s computer vision tools to diverse projects; check out this blog post for more examples.
In the future, Neural Pocket plans to reduce its reliance on real-world data and use synthetic data for as much as 90% of training data. The team’s confidence in Unity’s computer vision capabilities is a key factor driving this shift.
“With its active development focused on user’s needs, we expect the Unity Computer Vision Perception Package to keep improving over time, becoming a reference for perception tasks and a starting point for our perception projects,” said Angénieux.

“Unity’s computer vision tools enable us to work more quickly and cost-effectively. As a result, we can train and deploy our computer vision models at a fraction of the typical time and cost.”

“With the increase in variation of data that Unity Computer Vision provides, the necessity for real-world data collection is reduced. The performance of the computer vision models is also improved, resulting in higher-quality products.”